Agile usability testing

Posted on June 8, 2007 by matyeo
Most people agree that it would be good to conduct usability testing of the customer experience associated with their application or website, but many feel it will take too long or be too expensive. Over the years we have developed techniques which fit in well with the more agile development techniques being applied within many companies. Our techniques generally involve a small number of users and can be completed in 2 to 3 weeks or even less. The added value is that we are often able to test up to twice as many tasks within a given time period as can be done using more conventional techniques.
Method
In essence, we conduct a series of mini-usability tests, each with its own design, test, analysis and design recommendations components. These short iterations may take from a half day to a week to complete. When these techniques are combined with a rapid prototyping development environment, we are able to test, make recommendations, have the changes implemented, and validate the design changes within a couple of iterations -— generally less than a week.
This provides a quick way to measure and assess most major usability problems – both the ones anticipated or hypothesized and those unexpected issues which often surface during testing. Typically, the process involves seven steps:
- Identify the priority user tasks (most frequent or critical) which must be supported.
- Conduct an expert usability review to identify the obvious usability issues and have them fixed.
- Develop hypotheses regarding other potential problem areas which need to be tested.
- Conduct usability testing focused on those areas of uncertainty.
- Analyze the results and produce design recommendations to address the usability issues.
- Have the problems fixed in conjunction with the development team.
- Conduct the next iteration of testing and validate that the previous usability issues have been resolved.
Then we iterate this 7 step process 2 or 3 times…
The emphasis is on identifying and fixing usability problems as quickly as possible, verifying that the fix has been successful, and moving on to find new problems which may have been masked by other usability issues until these have been fixed (e.g. you won’t know if someone can use an input form if they can’t find the form).
Invariably, we encounter other usability issues which were not anticipated from the expert review. These are usually more prevalent with specialized applications or user groups, but are easily addressed using the same technique. The important point is to have some clear, overriding goals for the customer experience.
Working with marketing, product management, and/or development groups we establish a jointly agreed set of performance objectives for key tasks. For example, X% of people should be able to complete the task unaided within a specified period of time, number of page views, number of mouse clicks, etc. Having these types of hypotheses ahead of time helps to eliminate individual biases in interpreting user performance results and permits us to use some simple statistical techniques for quickly identifying significant usability issues. This is quite different from the “waterfall” method of product development, where the process is more linear and often problems are not found until the very end when it is very costly and time-consuming to make fixes.
How we design agile usability tests
WARNING: This article makes reference to non-parametric statistical techniques.
Reader discretion is advised.
We develop a set of high-priority tasks to be tested, typically 2 to 3 times as many as we can actually test with any one test participant. This provides us with a pool of tasks from which we can select substitute tasks, once we’ve determined that a problem exists. For example, Table 1 shows how substitution can actually test for 10 tasks even though only 5 tasks can be tested per session. It should be noted that the tasks are ordered 1 through 5 only for this example. In reality, we use a Latin Square technique to randomize the ordering of tasks in order to minimize any order effects.
Table 1: Task substitution over sessions
Example of task substitution over sessions, based on
obtaining significant results over 2 to 4 sessions. This permits
doubling of the number of tasks which can be tested.
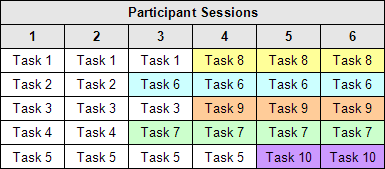
The savings accrue from being able to quickly identify usability issues associated with certain tasks and substitute new tasks for continued testing. Following a round of testing similar to that shown in Table 1 (6 test sessions), we would consider the best solutions to address the issues observed and recommend that some changes be made before the next round of testing so that certain tasks could be tested again with the revised user interface. In some cases we would have to gather more data to be certain whether the issue was significant enough to worry about. And, in other cases, the changes required might be too complex to manage between testing rounds. In these cases, we may conduct other types of tests with paper prototypes to explore the options we are considering for a more major or holistic redesign.
You’ll notice some tasks are swapped out after only 2 or 3 sessions and you may wonder why. Well, one of the things we commonly encountered using traditional usability techniques was that we’d expect something was going to be a problem, we’d observe it occurring for participant after participant and yet we’d keep testing that same task through to the end of the study. This was very wasteful of resources and went well past the point of diminishing returns.
The focus should be less about the number of users and
more about increasing the number of tasks tested.
In these studies, we are not trying to predict whether a politician will get 50 versus 54% of the votes. We are simply trying to prove or disprove a simple hypothesis based on the Binomial Distribution [1]. For example, let’s say we conservatively hypothesize that 9 out of 10 (90%) of people tested should be able to successfully complete a given task. How likely is it then for us to observe 2 or 3 people in a row who are unable to do so? It turns out to be not very likely at all. In fact, observing 2 failures in 4 people (as shown in Table 2) is still a significant result at the 0.05 level. That is, there is less than a 5% chance of observing this result simply by chance. Therefore, we can feel quite confident that the usability issue we are observing is significant and should be fixed.
| # of Participants Attempting Task | # of Participants Not Completing the Task | Significance (probability of occurring by chance) |
|---|---|---|
|
2
|
2
|
Yes ( p<0.05)
|
|
3
|
2
|
Yes ( p<0.05)
|
|
3
|
3
|
Yes ( p<0.01)
|
|
4
|
2
|
Yes ( p<0.05)
|
|
4
|
3
|
Yes ( p<0.01)
|
|
4
|
4
|
Yes ( p<0.001)
|
More often, product managers will not be satisfied with 10% of the user population having a problem. They will prefer to use a more stringent test and assume the failure rate should be less than 1 in 20 people, or 5%. In this case (see Table 3), the probability of 2 or 3 people in a small sample having difficulties are even less, often generating significant probabilities of less than 1 in 100 (1%).
| # of Participants Attempting Task | # of Participants Not Completing the Task | Significance (probability of occurring by chance) |
|---|---|---|
|
2
|
2
|
Yes ( p<0.01)
|
|
3
|
2
|
Yes ( p<0.01)
|
|
3
|
3
|
Yes ( p<0.001)
|
|
4
|
2
|
Yes ( p<0.05)
|
|
4
|
3
|
Yes ( p<0.001)
|
|
4
|
4
|
Yes ( p<0.001)
|
The end result is that most critical or major usability issues can be discovered and confirmed with only 3 or 4 people, resulting in considerable savings in time and money.
Benefits of agile usability testing
- Good focus on critical and high-priority items but still open to unexpected discoveries.
- Well suited to testing in conjunction with rapid prototyping environments.
- More problems found quicker and with less expense.
- More problems fixed and the fixes validated.
- Fixing problems early helps uncover other problems which might have gone unnoticed.
- Tightly integrated with design and development process.
Critical success factors
- Use of expert review to focus subsequent user testing on likely problem areas.
- Use of rapid prototyping tools to make quick changes.
- Culture focused on the user and the overall customer experience.
- Involvement of all stakeholders in the testing and resolution of usability issues.
- Empowerment of the team to make quick decisions and design changes.
- Agreement on key tasks and performance criteria.
- Access to members of the target audience.
- Ability to rapidly analyze test results and substitute new tasks.
Summary
Agile usability testing overcomes some common problems of usability testing:
- Not bringing the team together to get buy in to usability problems and solutions.
- Not testing enough tasks to uncover the majority of serious usability issues.
- Not iterating to test the effectiveness of recommended solutions.
Our experience has shown this type of agile usability testing produces informed decisions and solutions in the shortest amount of time.
URLs in this post:
[1] Binomial Distribution: http://en.wikipedia.org/wiki/Binomial_distribution